LinkedIn ha desarrollado un sistema de datos de código abierto para potenciar cargas de trabajo de análisis y machine learning. Utilizan datos para tomar decisiones y brindar a sus miembros mejores ideas sobre empleos y conexiones profesionales a nivel mundial.
Las implementaciones de este data lakehouse de código abierto se basan en motores de cálculo como Apache Spark, Trino y Apache Flink, almacenamiento distribuido como HDFS y almacenamiento en la nube, y catálogos de metadatos/formatos de tablas como Apache Iceberg, Delta, Hudi y Apache Hive Metastore. Los usuarios crean tablas relacionales sobre datos estructurados o semi-estructurados mediante motores de cálculo, con metadatos almacenados en un catálogo y datos en almacenamiento distribuido.
Aunque funcional, la gestión actual de tablas es fragmentada, con componentes independientes en un plano general de datos. La falta de un sistema de código abierto que los unifique es un desafío para simplificar la gestión del "lakehouse", optimizar consultas, establecer gobernabilidad y mejorar la experiencia del desarrollador. Los científicos de datos y otros profesionales deben lidiar con múltiples sistemas y gestionar tablas individualmente, lo que puede generar complejidad e inconsistencias.
Para abordar esto, LinkedIn ha creado OpenHouse, un sistema que permite a los desarrolladores interactuar con las tablas administradas en su data lakehouse. Con OpenHouse, se busca especificar declarativamente las definiciones y políticas de las tablas utilizando una API como SQL, para que el lakehouse se encargue del resto. Esto reduce la carga de trabajo para los desarrolladores y mejora la administración de tablas, brindando una experiencia más eficiente.
Linkedin desarrolló OpenHouse siguiendo cuatro principios rectores para permitir que los equipos de plataforma de datos y los usuarios de big data creen tablas completamente administradas, compartibles públicamente y gobernadas en implementaciones de lakehouse de código abierto:
1. Las tablas son la única abstracción API para los usuarios. Todos los accesos a los datos de las tablas deben realizarse a través de una interfaz de tabla, evitando lectura/escritura directa de archivos o blobs en almacenamiento distribuido.
2. Las tablas se almacenan en un espacio de nombres de almacenamiento protegido, lo que permite al sistema tener control total sobre la gestión, organización de datos, seguridad, disponibilidad y cuotas.
3. Las tablas están gobernadas según los estándares acordados por la empresa, lo que permite aplicar restricciones a modelos de datos, cumplimiento y otros metadatos.
4. Para asegurar un rendimiento óptimo, las tablas se mantienen regularmente mediante ajustes basados en estadísticas de consulta y la recopilación de versiones expiradas. La experiencia del usuario, denominada "Northstar", ofrece una fluidez para crear, manipular y compartir tablas a través de llamadas de API, con soporte para sintaxis estándar de SQL o Dataframe.
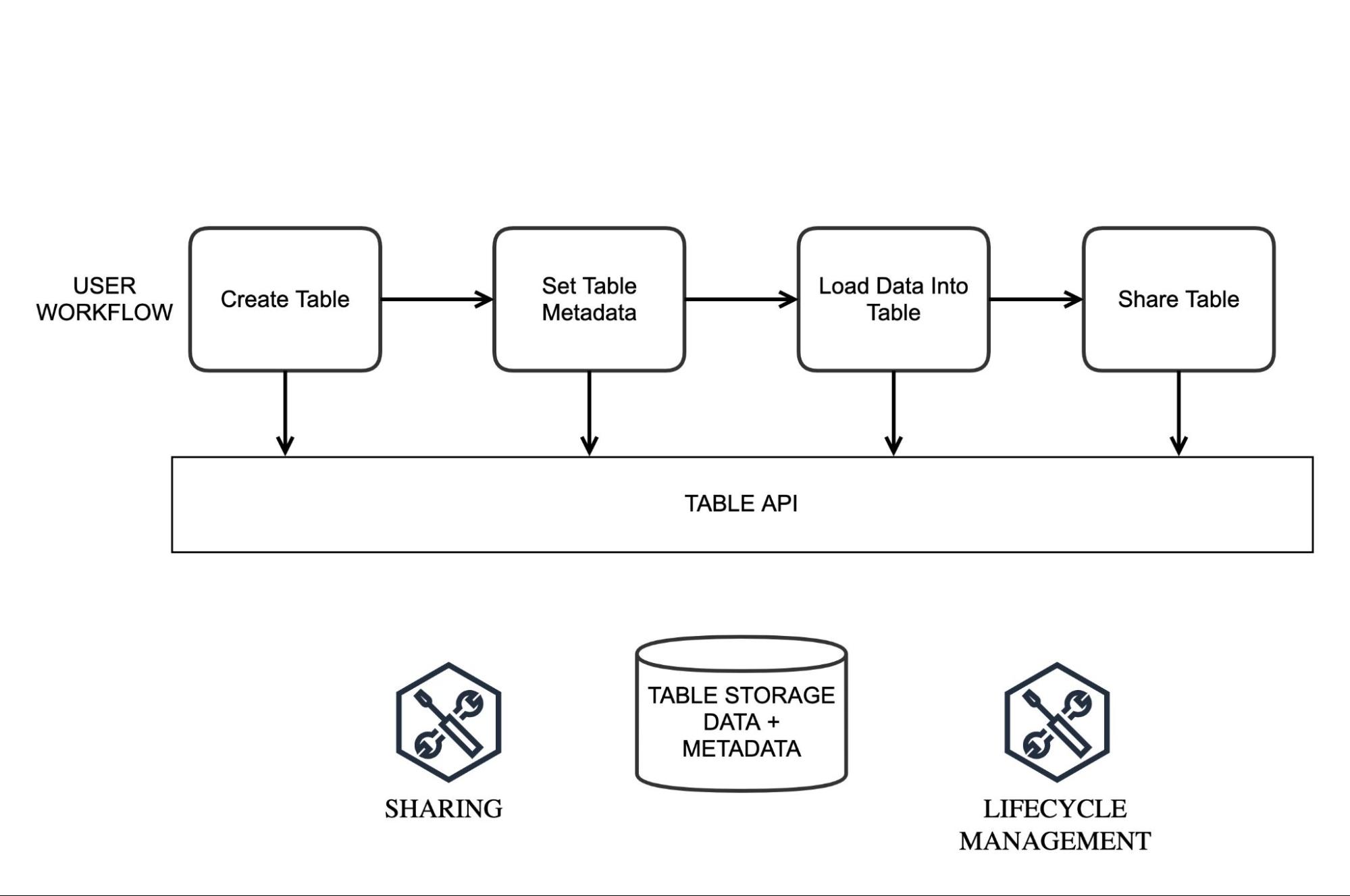
Figure 1: Northstart UX
La Figura 1 muestra la experiencia del usuario "Northstar" hacia la que OpenHouse se orienta. Este flujo permite a los usuarios crear una tabla, manipular los metadatos de la tabla, cargar datos y compartirlos mediante una única cadena de llamadas de API. En esta experiencia del usuario, la mayoría de las llamadas de API se pueden realizar aprovechando la sintaxis estándar de SQL o Dataframe.
RESUMEN:
LinkedIn ha desarrollado un sistema de datos de código abierto para análisis y machine learning, utilizando datos para ofrecer a sus miembros información sobre empleos y conexiones profesionales a nivel mundial.
La implementación de este data lakehouse de código abierto se basa en motores de cálculo como Apache Spark, Trino y Apache Flink, almacenamiento distribuido como HDFS y almacenamiento en la nube, y catálogos de metadatos/formatos de tablas como Apache Iceberg, Delta, Hudi y Apache Hive Metastore.
Para abordar la fragmentación en la gestión de tablas, LinkedIn ha creado OpenHouse, un sistema que permite a los desarrolladores interactuar con las tablas administradas en su data lakehouse, especificando declarativamente las definiciones y políticas de las tablas utilizando una API como SQL.
Los principios rectores de OpenHouse incluyen utilizar tablas como la única abstracción API para los usuarios, almacenar las tablas en un espacio de nombres de almacenamiento protegido, gobernar las tablas según los estándares de la empresa y mantener regularmente las tablas para asegurar un rendimiento óptimo.
La experiencia del usuario “Northstar” en OpenHouse permite a los usuarios crear, manipular, cargar y compartir tablas con una sola cadena de llamadas de API, aprovechando la sintaxis estándar de SQL o Dataframe.